Your AI Agent Is Only as Good as the Data It Queries
by Beth Barach, VP of PM//9 min read/

Enterprise security teams are building their own AI. Not evaluating it, not piloting it, building it. Internal AI platforms, custom agents wired into existing workflows, LLM-powered dashboards that surface risk to the board in plain language. The investment is real and accelerating.
But there is a problem almost nobody talks about in the rush to build. The agent is the easy part, it’s the data that’s the hard part. And in exposure management specifically, the data is almost universally not ready for an AI agent to query against.
The Data Problem Under Every AI Initiative
Exposure management data is messy by nature. You have dozens of security tools scanning the same environment, each with its own data model, its own asset identifiers, its own severity scores. Each tool sees the same asset differently. None of them know about the business context that would tell you whether that asset actually matters. None of them talk to each other.
The result is fragmentation at scale. Duplicate findings that look like separate vulnerabilities. Assets with no owner because the identity data lives in a different system. Severity scores that contradict each other depending on which scanner ran last. Remediation backlogs that grow because no one can confidently say what to fix first.
When you point an AI agent at that data, the output reflects the input. Faster noise is not a better security outcome. Speed without accuracy isn't progress. An agent acting on inconsistent data just automates the wrong priorities.
This is not a model problem. It is a data problem. And it is the problem that has to be solved before AI-driven exposure management can deliver on what it promises.
What It Actually Takes to Build a Trustworthy Data Foundation
Most teams attempting to build AI-driven exposure management hit the same ceiling: they can build the agent, but they can't fix the data underneath it.
Building that foundation means solving three hard problems that most point solutions cannot address on their own.
- Unification across every source. Every scanner, cloud provider, identity system, and business context source needs to feed into a single model. Not a report. A connected, relationship-driven data model where an asset knows what findings are on it, what team owns it, what business function it supports, and what threat intelligence applies to it. That context is what separates prioritization from guessing.
- Deduplication and normalization. When multiple tools report on the same asset or the same vulnerability, you need a system that resolves those conflicts and produces a single authoritative record — One finding. One asset. One authoritative record your team can act on. Getting there requires configurable source precedence, field-level attribute mapping, and conflict resolution logic that has been tested and validated across hundreds of real enterprise environments.
- Explainability at the data layer. Any AI recommendation that comes out of this system has to be traceable. Not "the model said so" — but here is the specific record, here is the source data that produced it, here is the mapping rule that resolved the conflict. That is the level of auditability that compliance teams, legal teams, and boards actually require before they trust AI-driven decisions in security.
How Brinqa Unifies Exposure Data for AI
This is exactly the problem Brinqa was built to solve — not as a feature, but as the core architectural premise of the platform.
Brinqa’s CyberRisk Graph™ is the relationship-driven data model at the heart of our platform. It is not a static snapshot. It is a living model that continuously updates as environments change, new sources connect, and context evolves. Every entity in the graph is a typed node — assets, findings, identities, business context, threat intelligence. Every connection is a typed relationship with defined semantics. An asset is owned by a team. A finding is discovered on an asset. A vulnerability is associated with an attack technique. These are not inferred connections. They are explicitly defined, validated, and maintained.
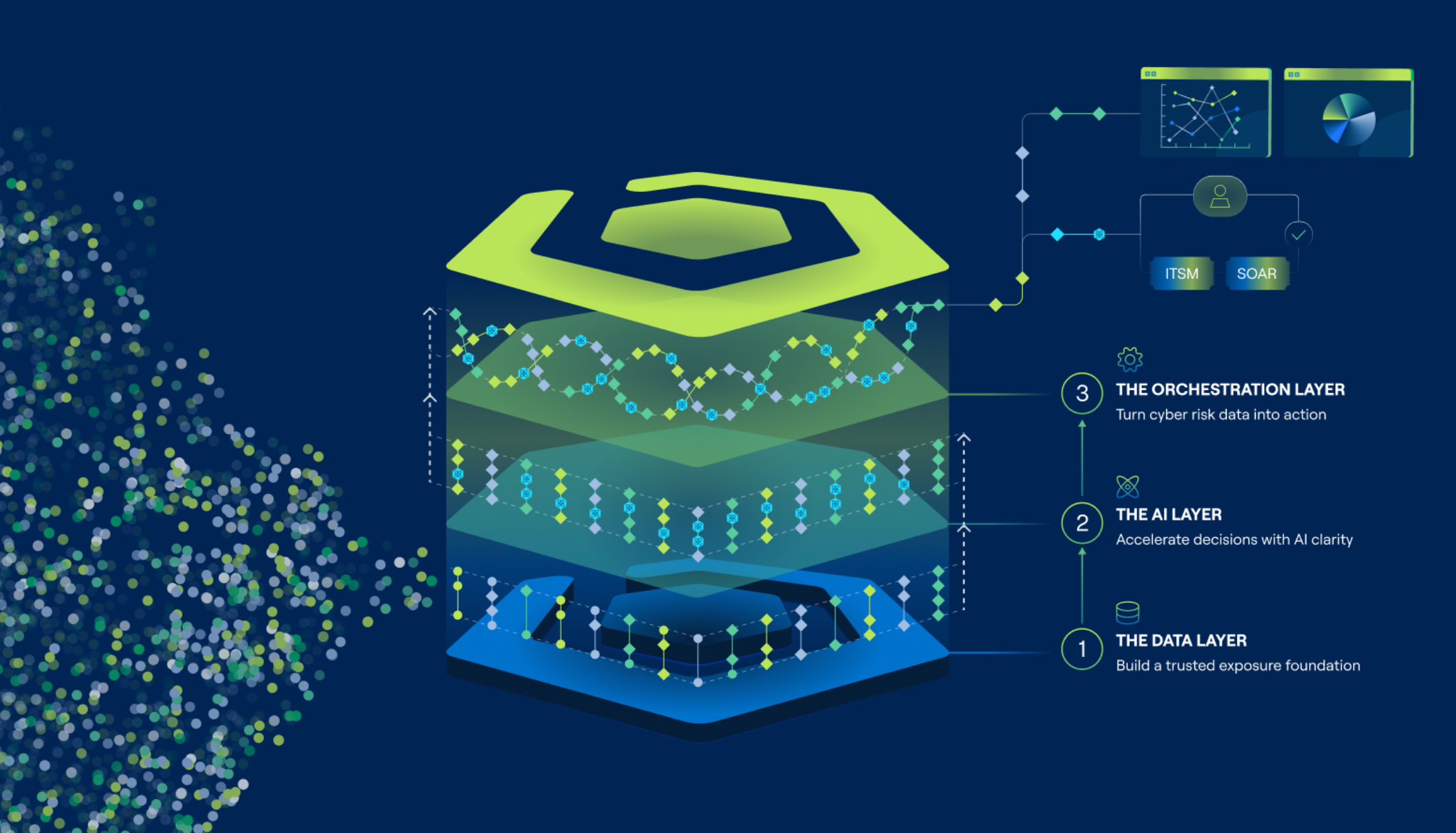
This structure produces a single, authoritative representation of each object in the graph. When multiple security tools report on the same asset or vulnerability, Brinqa's attribute mapping framework resolves conflicts through configurable source precedence. Every AI recommendation Brinqa produces can be traced back through the graph to the authoritative record that informed it, and from that record to the source data and mapping rules that produced it.
With 260+ pre-built connectors, the largest portfolio in the industry, Brinqa integrates across IT, security, and business systems. Each connector carries field-tested attribute mapping configurations built from real enterprise deployments. A team connecting their existing scanner stack inherits that institutional knowledge before writing a single configuration line of their own.
That foundation is what makes the AI layer trustworthy, and it is what Brinqa's native AI agents are built directly on top of. Each one closes a specific gap in the journey from raw exposure data to confident action.
- The AI Attribution Agent predicts remediation ownership when source data is incomplete — one of the most common blockers that keeps teams stuck before they can even start prioritizing.
- The AI Deduplication Agent identifies and merges duplicate findings from multiple scanners into a single consolidated record, reducing noise and giving remediation teams clearer, unified instructions.
- The AI Exploitability Agent delivers exploitability-based prioritization by evaluating whether a vulnerability is actually reachable and dangerous in your specific environment — not just whether it is exploitable in theory, but whether it is exploitable given your controls, your network topology, and your business context.
Every output is traceable. Every recommendation has a lineage back to the data that produced it.
Where Your AI Agent Fits In
Here is where BYOAI comes in, and the framing matters.
Brinqa's Bring Your Own AI (BYOAI) model gives security teams a choice: use Brinqa's native AI agents out of the box, or connect an existing agent directly to Brinqa's governed exposure data via API or MCP. Either way, every AI recommendation runs on the same CyberRisk Graph™ — grounded in gold records, traceable to source data, and explainable at every step.
Brinqa's native agents cover a lot of ground. But enterprises are building their own AI. Internal platforms, custom workflows, BI tools the data science team spent months configuring, co-pilots wired into the security operations center. That investment is real, and it should not be set aside to adopt a vendor's AI stack wholesale.
The question is: what data does your agent run on?
Brinqa supports connecting an external AI agent directly to the CyberRisk Graph. Your agent submits queries in natural language, which Brinqa translates into BQL (Brinqa Query Language) and executes against the graph. Authoritative, unified data comes back. Your agent acts on it.
Connection paths include the BQL API for agent-to-platform queries, MCP (Model Context Protocol) for machine-to-machine integration into enterprise AI ecosystems, and BrinqaDL SQL/API for BI tools and analytics platforms that need direct access to long-term exposure data storage.
What this means in practice: your agent gets the full benefit of the data foundation — the unification, the deduplication, the business context, the authoritative records — without rebuilding any of it. The AI strategy stays yours, and the data integrity is guaranteed.
For teams building toward a continuous threat exposure management (CTEM) program, the data foundation described here is not optional, it's the baseline CTEM execution requires. Unified, deduplicated, and contextualized exposure data is what separates a CTEM program that moves from one that measures.
The Principle That Guides This
The insight the best exposure management programs have reached is the same one that applies to AI: the outcomes are only as good as the data.
Most organizations spend too much time on the AI layer and not enough on the data layer. The same pattern shows up in vulnerability management programs that invest in tooling before fixing the underlying data end up with faster noise, not better outcomes. They optimize the model while the inputs stay fragmented. The result is sophisticated-looking outputs built on a foundation that cannot support them.
Get the foundation right — unified, deduplicated, contextualized, explainable — and the AI agents querying it can deliver on what they promise. That is the bet we made when we built the CyberRisk Graph, and it is why we opened it up for your agents to query.
If you’re evaluating the data foundation your AI agents run on, speak with a Brinqa expert about how the CyberRisk Graph works with your environment.
FAQs
AI-driven exposure management fails when the underlying data is fragmented. Most enterprise environments feed multiple scanners and security tools into the same environment, producing duplicate findings, conflicting severity scores, and assets with missing ownership data. When an AI agent queries that data, it inherits all of those inconsistencies. The output reflects the input. Clean, deduplicated, and contextualized data is the prerequisite for trustworthy AI output in security.
The Brinqa CyberRisk Graph is a relationship-driven data model that continuously maintains a unified, authoritative representation of an enterprise's security environment. Every asset, finding, identity, and business context element is a typed node. Every connection is a typed relationship with defined semantics. When an external AI agent queries the graph via BQL API or MCP, it receives deduplicated, contextualized, authoritative data rather than raw scanner output. This makes the Cyber Risk Graph the data foundation for both Brinqa’s native AI agents and enterprise-built custom agents.
Brinqa’s AI Deduplication Agent identifies findings reported by multiple scanners that represent the same underlying vulnerability and merges them into a single consolidated record. The process uses configurable source precedence and field-level attribute mapping built from real enterprise deployments. The result is one authoritative record per finding, with unified remediation instructions and a traceable lineage back to the source data that produced it.
BYOAI (Bring Your Own AI) in exposure management refers to the practice of connecting an enterprise’s internally built AI agent — whether a custom LLM workflow, BI tooling, or security operations co-pilot — directly to a trusted, unified data source. In Brinqa’s model, external agents submit natural-language queries that are translated into BQL and executed against the Cyber Risk Graph. The agent receives authoritative, deduplicated exposure data without needing to rebuild the data foundation itself.
Security decisions increasingly require board-level and legal accountability. An AI recommendation that cannot be traced to a specific data record, source system, and mapping rule cannot be audited — and cannot be trusted by compliance teams or legal. Brinqa builds explainability at the data layer: every AI output is traceable through the Cyber Risk Graph to the authoritative record and the source data that produced it. This is the standard that enterprise security programs require before acting on AI-driven prioritization.
Brinqa’s cyber risk prioritization combines exploitability assessment with business context. The AI Exploitability Agent evaluates whether a vulnerability is reachable and dangerous within a specific environment — accounting for network topology, active controls, and business function. The AI Attribution Agent ensures each finding has a confirmed owner before prioritization begins. This layered approach produces a risk-ordered remediation list that reflects actual exposure, not scanner severity scores in isolation.


